
통계 컴퓨팅이란?
“통계 컴퓨팅(statistical computing)”이란 단순히 숫자를 계산하는 것이 아니다. 데이터를 다루고 분석하며, 시각화하고 결과를 프로그래밍적으로 구현하는 모든 과정을 포함하는 넓은 개념이다.
통계 컴퓨팅은 다음과 같은 작업을 포함한다.
- 데이터 처리 및 변환 (data manipulation)
- 통계 모델링과 분석 (statistical modeling)
- 시각화 (graphics)
- 시뮬레이션 (예: 몬테카를로 시뮬레이션)
- 프로그래밍 (모듈화, 함수 작성, 디버깅 등)
이러한 작업을 쉽게 수행할 수 있도록 만들어진 언어가 바로 R이다.
R 문법의 기초
R은 인터프리터 언어다. 즉, 우리가 콘솔에 한 줄을 입력하면 R이 바로 실행 결과를 보여준다. 반면 여러 줄의 코드를 작성할 때는 .R 파일에 저장하고 ’source()’로 실행한다.
하지만 어떤 방식이든 실행되는 단위는 항상 “표현식(expression)”이다.
표현식(Expression)이란?
표현식이란 R에서 하나의 실행 가능한 코드 단위를 의미한다. 이 표현식은 즉시 실행되며, 결과값을 반환하거나 객체에 할당된다.
3 + 4 # 표현식 1: 계산
x <- 10 # 표현식 2: 변수 할당
mean(x) # 표현식 3: 함수 호출
R 표현식의 7가지 유형
리터럴 (Literals)
정의: 그 자체로 값을 나타내는 고정된 데이터.
42 # 숫자형 literal
"hello" # 문자형 literal
TRUE, FALSE # 논리형 literal
NA # 결측값 literal리터럴은 변수에 할당하지 않아도 R에서 인식되는 기본적인 데이터다. 표현식으로 사용되면 결과값이 그대로 출력된다.
함수 호출 (Function Call)
정의: 이름이 있는 함수를 괄호 ()와 함께 호출하는 표현식. 괄호 안에는 인자(argument)를 넘긴다.
mean(c(1, 2, 3))
sqrt(16)
sum(1:10)
할당문 (Assignment)
정의: 값을 객체에 저장하는 표현식. <-, =, assign() 등을 사용한다.
x <- 5
y = c(1, 2, 3)
assign("z", mean(y)) # z = 2
조건문 (Conditionals)
정의: 특정 조건을 비교하고 그 결과를 TRUE/FALSE로 반환하는 표현식.
> x > 3
[1] TRUE
> x == 5
[1] TRUE
> x != 2
[1] TRUE
흐름 제어문 (Flow-of-control statements)
if: 조건에 따라 실행
x <- 3
if (x > 0) {
print("+")
} else {
print("-")
}- if 뒤의 조건식은 반드시 하나의 논리값(TRUE/FALSE)을 반환
- else는 선택사항이며, 조건이 거짓일 때 실행
x <- 5
y <- 0
if (x > 0 && y != 0 && (x / y) > 1) {
print("Valid condition")
} else {
print("Invalid or unsafe")
}a <- 0
b <- 10
if (a == 0 || (b / a) > 1) {
print("Safe OR condition")
} else {
print("Unsafe division")
}
&&, ||와 같은 short-circuit 연산자를 사용할 수도 있다. 이 연산자들은 오직 첫 번째 요소만 검사하며 필요할 경우에만 두 번째 조건을 평가한다.
ifelse(): 벡터 조건 처리
x <- c(5, 10, 7)
ifelse(x %% 5 == 0, "x is a multiple of 5", "x is not a multiple of 5")
ifelse(condition, value_if_true, value_if_false) 구조이며, 조건의 길이에 따라 결과도 벡터로 반환한다.
루프 (Loops)
for 문: 지정된 횟수만큼 반복
for (i in 1:3) {
print(paste("i is", i))
for (j in 1:5){
print(paste("j is", j))
}
}이 코드는 이중 반복문 구조로, i가 바뀔 때마다 j가 1부터 5까지 도는 구조다.
x <- c(1, 2, 3, 4, 5, 6)
y <- c(2, 4, 1, 8, 6, 7)
ind <- c("A", "A", "A", "B", "B", "B")
xc <- split(x, ind) # $A: 1,2,3 $B: 4,5,6
yc <- split(y, ind) # $A: 2,4,1 $B: 8,6,7
par(mfrow = c(1, 2))
for (i in 1:length(yc)) {
plot(xc[[i]], yc[[i]])
abline(lsfit(xc[[i]], yc[[i]]))
}
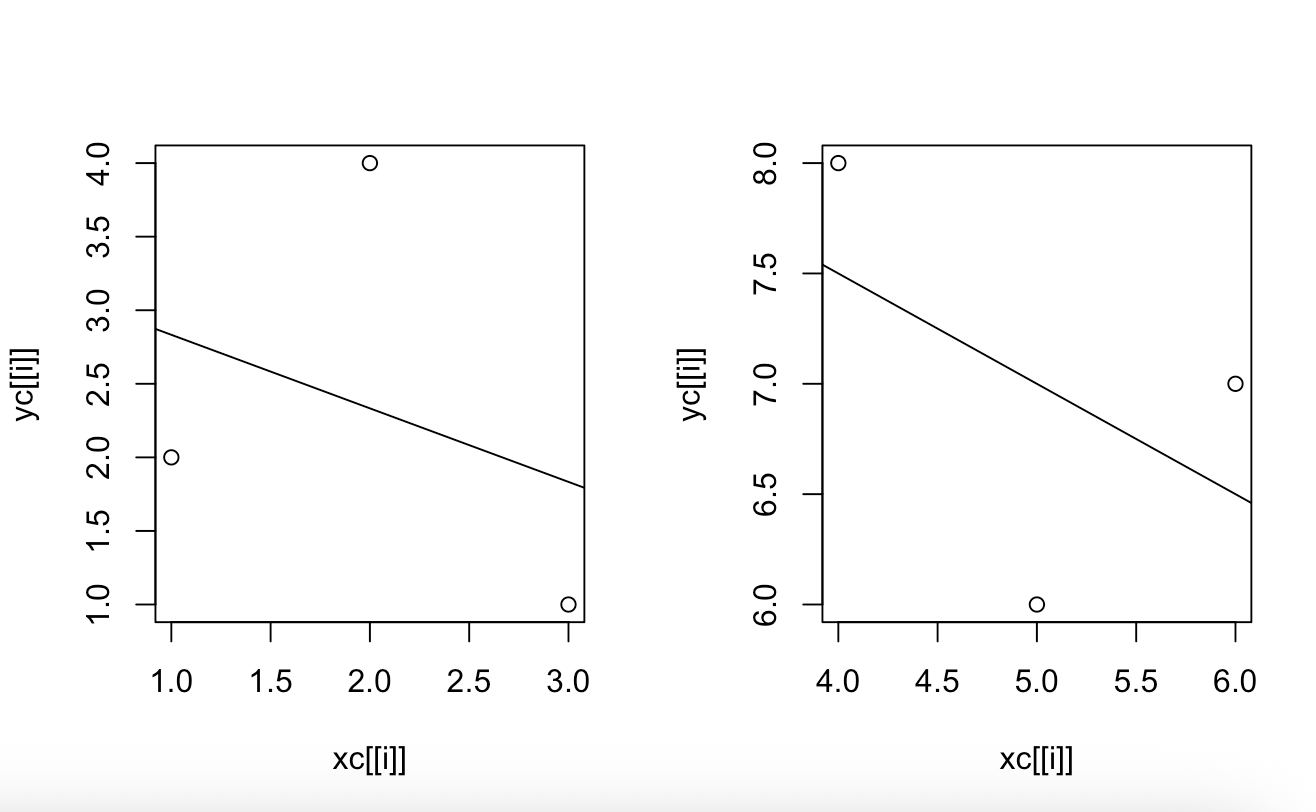
- x와 y는 각각 관측값을 담은 벡터
- ind는 각 관측값이 속한 그룹을 나타내는 벡터로, "A" 그룹과 "B" 그룹 두 가지가 있다
- split() 함수는 벡터를 그룹별로 쪼개어 리스트 형태로 저장
- 결과는
- xc 리스트는 $A: 1, 2, 3, $B: 4, 5, 6
- yc 리스트는 $A: 2, 4, 1, $B: 8, 6, 7
- par(mfrow = c(1, 2))는 그래프 창을 1행 2열로 나누어, 한 화면에 두 개의 그래프가 나란히 그려지도록 설정
- for 반복문을 이용해 각 그룹별로 plot() 함수로 산점도를 그림
- xc[[i]]는 xc 리스트에서 i번째 그룹의 x값 벡터를 의미함
- yc[[i]]도 마찬가지로 i번째 그룹의 y값 벡터다
- lsfit(xc[[i]], yc[[i]]) 함수는 각 그룹 데이터에 대해 최소제곱법 선형 회귀모형을 구함
- abline() 함수는 구한 회귀모형을 기준으로 회귀선을 플롯에 그림
while 문: 조건이 참일 동안 반복
count <- 1
while (count <= 5) {
print(count)
count <- count + 1
}조건이 참인 동안 코드를 계속 반복한다.
repeat 문: 무한 반복 (조건 없이 시작)
x <- 1
repeat {
if (x > 5) break
print(x)
x <- x + 1
}repeat는 조건 없이 무조건 반복하며, 반드시 내부에서 break로 종료해야 한다.
break / next
- break: 루프를 즉시 종료
- next: 해당 반복만 건너뛰고 다음 반복으로 이동
for (i in 1:5) {
if (i == 3) next
print(i)
}
# 출력: 1 2 4 5
벡터
벡터(vector)는 R에서 가장 기본적인 데이터 구조다. 숫자, 문자, 논리값 등 다양한 유형이 가능하다.
x <- c(10.4, 5.6, 3.1, 6.4, 21.7)- c() 함수는 여러 숫자를 연결(concatenate)하여 벡터를 생성
- <- 기호는 값을 객체에 할당(assign)하는 연산자로, x = ...와 동일하게 사용할 수 있음
- 방향을 바꾼 할당도 가능
x <- c(1,2,3,4,5)
y <- c(x, 0, x) # x 2회 + 0을 붙인 벡터 (길이 11)
y
v <- 2*x + y + 1 # 벡터 간 연산, 1은 11번 반복됨
# 4 7 10 13 16 3 6 9 12 15 8
벡터 길이가 다를 경우, 짧은 벡터가 긴 벡터의 길이에 맞게 자동 반복(recycling)된다.
x = 1, 2, 3, 4, 5
y = 1, 2, 3, 4, 5, 0, 1, 2, 3, 4, 5
2*1 + 1 + 1 = 4
2*2 + 2 + 1 = 7
2*3 + 3 + 1 = 10
2*4 + 4 + 1 = 13
2*5 + 5 + 1 = 16
2*1 + 0 + 1 = 3
이런 식으로 진행된다.
다음 글에서 계속됩니다!