
데이터 전처리(Data Preprocessing)는 데이터 사이언스 및 머신 러닝 프로젝트에서 원시 데이터를 분석 가능한 형태로 준비하는 과정입니다. 우선, 연속 변수를 숫자형으로 변환하는 것은 필수적입니다. 연속 변수가 숫자형으로 변환되면, 이를 기반으로 통계적 분석과 머신 러닝 모델링을 효과적으로 수행할 수 있습니다. 연속 변수를 숫자형으로 변환하는 과정에서 중요한 점 중 하나는, 특정 변수들이 예상과 다르게 object 타입으로 저장되어 있을 수 있다는 것입니다. 예를 들어, emp_length라는 변수는 숫자형으로 처리되어야 하지만 현재는 object 타입으로 되어 있을 수 있습니다.

df['emp_length'] 열의 문자열에서 특정 패턴을 제거하고, 이 데이터를 정수형 형태로 변환하기 위해 여러 단계를 수행해야 합니다. str.replace()는 문자열에서 특정 패턴을 다른 문자열로 교체하는 함수입니다.
Syntax:
Series.str.replace(pat, repl, n=-1, case=None, regex=True)
Parameters:
pat: string or compiled regex to be replaced
repl: string or callable to replace instead of pat
n: Number of replacements to make in a single string, default is -1 which means all.
case: Takes boolean value to decide case sensitivity. Make false for case insensitivity
regex: Boolean value, if True assume that the passed pattern is a regex
Return Type:
Series with replaced text values
이때, str(0)은 정수 0을 문자열로 변환한 것입니다. 즉, str(0)은 문자열 '0'을 생성합니다. 두 번째 단계부터 df['emp_length_int'] = df['emp_length_int'].str.replace를 사용하는 이유는 첫 번째 단계에서 df['emp_length_int'] 열이 업데이트되었기 때문입니다.

문자를 제거했으니 데이터를 정수형 형태로 변환합니다. pd.to_numeric()는 pandas 라이브러리에서 문자열을 숫자형으로 변환하는 함수입니다. 이 함수는 주어진 시리즈나 데이터프레임의 열을 정수형(int) 또는 실수형(float)으로 변환합니다.
Syntax: pandas.to_numeric(arg, errors=’raise’, downcast=None)
Parameters:
arg : list, tuple, 1-d array, or Series
errors : {‘ignore’, ‘raise’, ‘coerce’}, default ‘raise’
-> If ‘raise’, then invalid parsing will raise an exception
-> If ‘coerce’, then invalid parsing will be set as NaN
-> If ‘ignore’, then invalid parsing will return the input
downcast : [default None] If not None, and if the data has been successfully cast to a numerical dtype downcast that resulting data to the smallest numerical dtype possible according to the following rules:
-> ‘integer’ or ‘signed’: smallest signed int dtype (min.: np.int8)
-> ‘unsigned’: smallest unsigned int dtype (min.: np.uint8)
-> ‘float’: smallest float dtype (min.: np.float32)
Returns: numeric if parsing succeeded. Note that return type depends on input. Series if Series, otherwise ndarray.
이 코드는 df['emp_length_int'] 열의 값을 숫자형으로 변환하여 다시 df['emp_length_int']에 저장합니다.

같은 방식으로 df['term']도 숫자형으로 변환합니다.
earliest_cr_line를 살펴봅시다. earliest_cr_line (최초 신용 한도 날짜)는 차용자가 처음으로 신용 카드나 대출을 개설한 날짜를 말합니다. 신용 리스크 분석에서는 이 날짜가 중요합니다. 왜냐하면, 차용자가 오랜 기간 동안 신용 한도를 유지하면서 채무 불이행 없이 관리해 왔다면, 신용도가 더 높게 평가될 수 있기 때문입니다. 예를 들어, 차용자가 수년 전에 최초 신용 한도를 개설했다면, 오랜 신용 관리 기록 덕분에 더 신뢰할 수 있는 것으로 보일 수 있습니다.
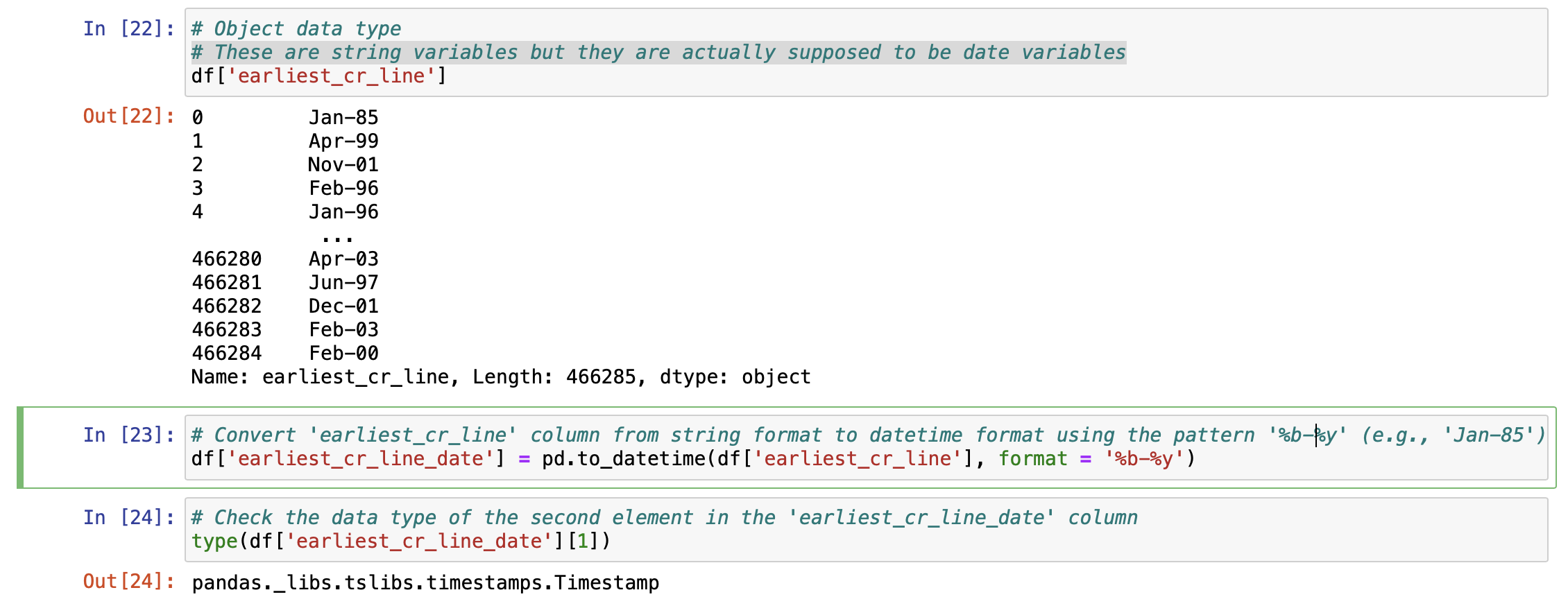
earliest_cr_line 열을 문자열 형식에서 날짜 형식으로 변환하려면, 패턴 '%b-%y'를 사용합니다.
Syntax: pandas.to_datetime(arg, errors=’raise’, dayfirst=False, yearfirst=False, utc=None, box=True, format=None, exact=True, unit=None, infer_datetime_format=False, origin=’unix’, cache=False)
Parameters:
arg: An integer, string, float, list or dict object to convert in to Date time object.
dayfirst: Boolean value, places day first if True.
yearfirst: Boolean value, places year first if True.
utc: Boolean value, Returns time in UTC if True.
format: String input to tell position of day, month and year.
Return type: Datetimeformat는 문자열을 날짜 형식으로 변환할 때 사용하는 날짜와 시간 형식의 문자열을 지정하는 매개변수입니다. 기본값은 None입니다.
format에 지정된 형식에 따라 문자열이 날짜로 해석됩니다. 예를 들어, "%d/%m/%Y"는 "일/월/연도" 형식의 날짜 문자열을 파싱하는 데 사용됩니다.
여기서 각 기호의 의미는 다음과 같습니다:
- %d: 일을 두 자리 숫자로 표현 (예: 01, 31)
- %m: 월을 두 자리 숫자로 표현 (예: 01, 12)
- %Y: 연도를 네 자리 숫자로 표현 (예: 2024)
예를 들어, "15/08/2023"이라는 문자열이 "%d/%m/%Y" 형식을 사용하여 날짜로 변환되면, 2023년 8월 15일로 해석됩니다.
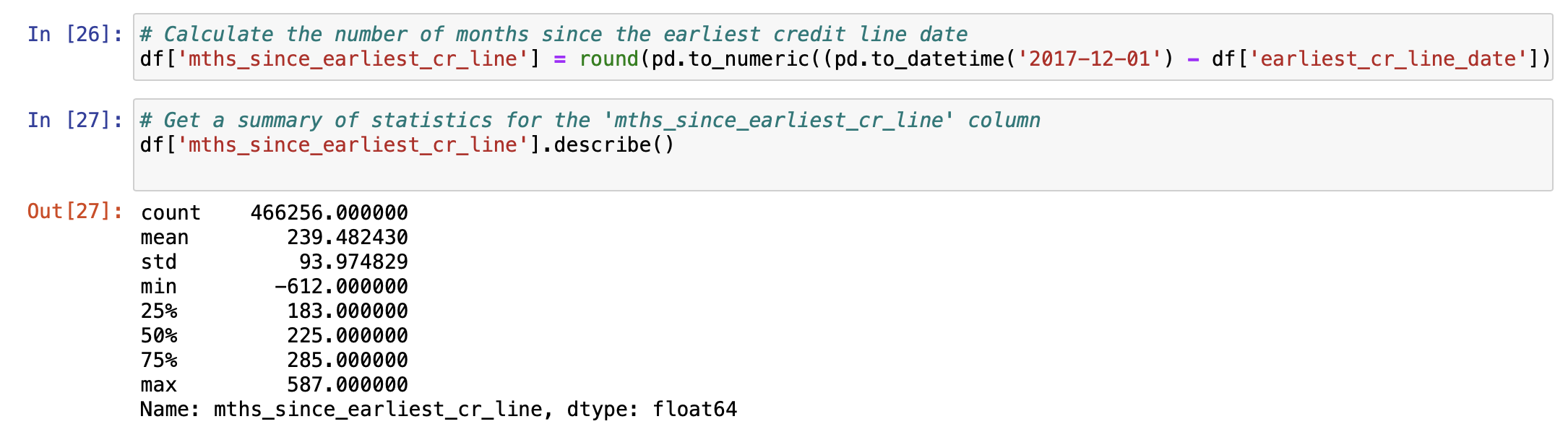
earliest_cr_line_date 열의 날짜와 기준 날짜인 '2017-12-01' 사이의 월 수를 계산하여 mths_since_earliest_cr_line이라는 새로운 열에 저장합니다. 이때, np.timedelta64는 결과를 월 단위로 변환합니다. np.timedelta64(1, 'M')는 1개월을 나타내는 Timedelta 객체입니다. 따라서 날짜 차이를 월 단위로 나누는 것입니다.
그 후 통계 요약 정보를 살펴봅니다. 최소값이 -612개월인 것은 데이터에 문제나 오류가 있을 수 있음을 나타냅니다.
# Display rows where 'mths_since_earliest_cr_line' is negative
df.loc[df['mths_since_earliest_cr_line'] < 0, ['earliest_cr_line', 'earliest_cr_line_date', 'mths_since_earliest_cr_line']]
earliest_cr_line 열을 문자열 형식에서 날짜 형식으로 변환할 때 문제가 생긴 것임으로 예측할 수 있습니다. 예를 들어, 'Sep-62'가 2062-09-01로 변환되었고, 실제로는 1962-09-01이어야 했습니다. 이 문제는 기본 날짜 변환 스케일이 1970년 이후부터 시작되기 때문에 발생했습니다.
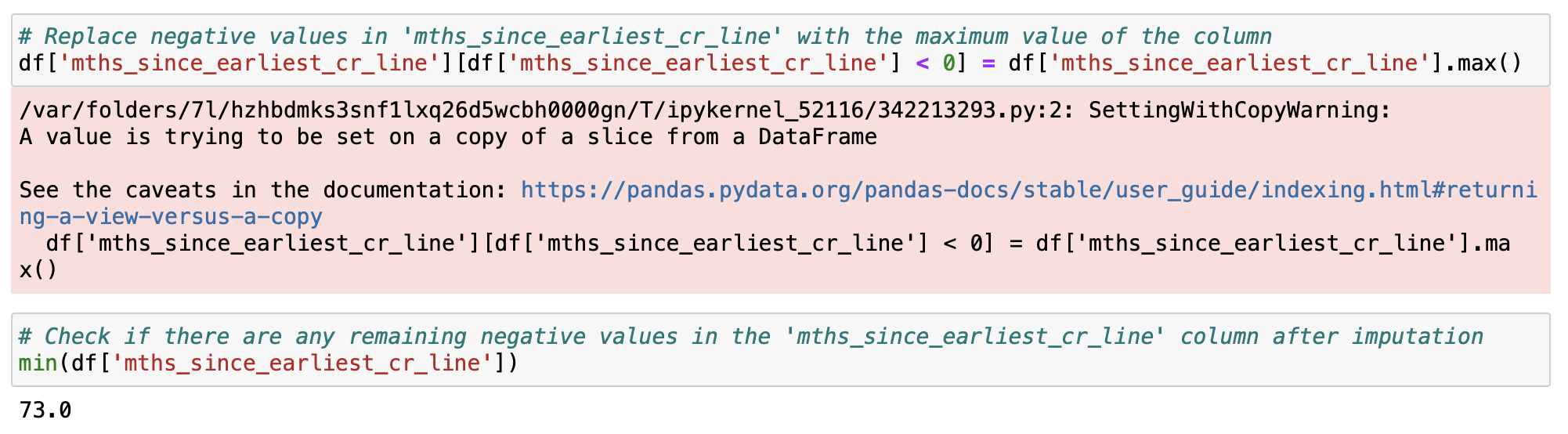
'mths_since_earliest_cr_line' 열의 음수 값을 해당 열의 최대값으로 대체하여 해결합니다. 같은 방식으로 issue_d를 프리프로세싱 해줍니다.
위와 같은 변수는 Continuous Variable (연속형 변수)이라고 부릅니다. 이는 값이 무한히 세밀하게 나뉠 수 있으며, 예를 들어, 시간, 거리, 온도와 같은 데이터가 여기에 해당합니다. 이제 Discrete Variable (이산형 변수)에 대해서도 살펴보겠습니다. 이산형 변수는 정수 값만을 가지며, 예를 들어, 사람의 수, 제품의 종류, 설문조사의 선택지와 같은 데이터가 이에 해당합니다. 이산형 변수는 연속적인 값을 가지지 않으며, 특정한 범위 내에서만 값이 존재합니다.

예를 들어, grade는 Discrete Variable (이산형 변수)이자 Categorical Variable (범주형 변수)에 해당합니다. 이러한 변수는 특정한 값들이 명확하게 구분되며, 각 값이 특정 카테고리를 의미합니다. 이 경우, 'grade' 변수는 다양한 등급을 나타내며 각 등급이 서로 다른 범주로 나뉩니다. 예를 들어, 'grade' 변수의 값이 'A', 'B', 'C', 'D'와 같이 여러 등급으로 나뉘어 있다면, 이 변수는 범주형 변수입니다. 동시에, 이러한 범주들은 이산형 변수로, 값들이 유한하고 셀 수 있습니다.
이러한 범주형 변수를 머신러닝 모델에서 효과적으로 활용하기 위해 One-Hot Encoding (원-핫 인코딩)을 적용할 수 있습니다. 원-핫 인코딩은 각 카테고리를 이진 변수로 변환하여, 모델이 각 범주를 독립적인 변수로 인식할 수 있도록 합니다. 예를 들어, 다음과 같은 원-핫 인코딩 결과를 볼 수 있습니다.

첫 번째 행에서 'B' 값이 1로 표시되고 나머지 값들은 0입니다. One-Hot Encoding은 범주형 변수를 이와 같이 이진 변수로 변환하여, 데이터 분석 및 머신러닝 모델에 활용할 수 있도록 합니다.
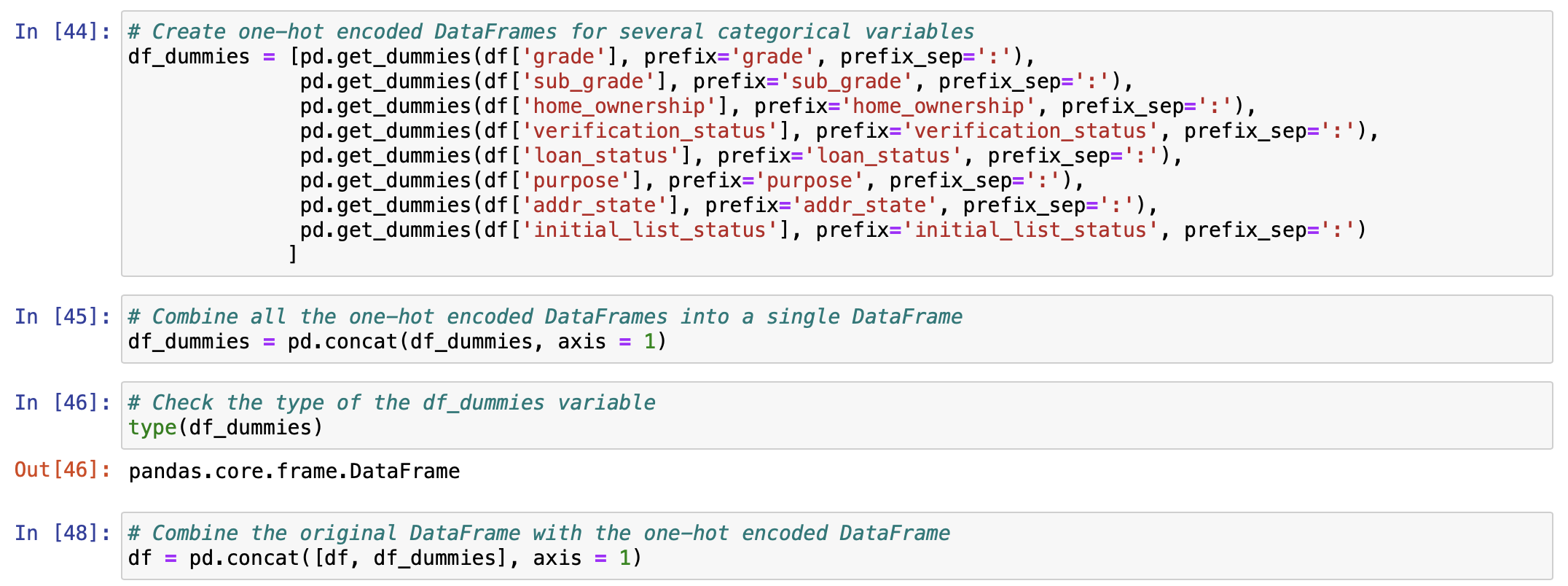
여러 범주형 변수를 대상으로 One-Hot Encoding을 적용하여 새로운 DataFrame을 생성합니다.
데이터셋에서 어떤 변수(열)에 데이터가 존재하지 않을 때, 이를 결측값이라고 합니다. 결측값이 많으면 분석 결과에 영향을 미칠 수 있기 때문에, 이를 처리하는 것이 중요합니다.
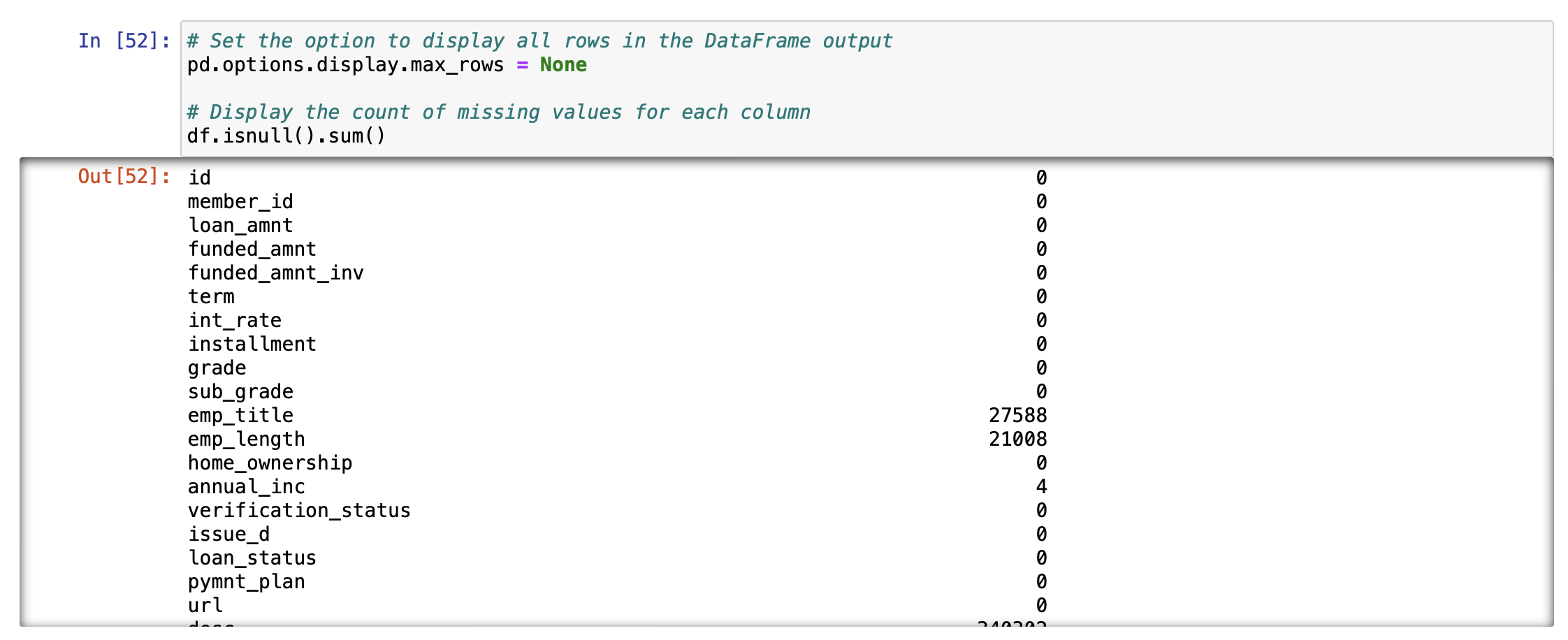
DataFrame의 모든 행을 출력할 수 있도록 설정한 후, 각 열의 결측값(missing values) 개수를 계산하여 출력하는 과정입니다. df.isnull().sum()은 각 열에서 결측값의 수를 계산하는 함수입니다. isnull() 함수는 데이터프레임 내의 값이 결측값인지를 검사하여, 결측값인 경우 True를 반환하고, 그렇지 않은 경우 False를 반환합니다. 그 후, sum() 함수가 True 값을 1로 간주하여 각 열의 결측값 개수를 합산합니다.
결측값을 처리하는 방법에는 여러 가지가 있으며, 데이터의 특성과 분석 목적에 따라 적절한 방법을 선택해야 합니다. 일반적인 결측값 처리 방법은 다음과 같습니다:
- 결측값 제거:
- 결측값이 있는 행(row)이나 열(column)을 삭제하는 방법입니다. 데이터에서 결측값이 매우 적을 때 유용합니다. 하지만 중요한 데이터가 삭제될 수 있기 때문에 신중하게 사용해야 합니다.
- 예시: df.dropna() (결측값이 있는 행 삭제)
- 평균, 중앙값 또는 최빈값으로 대체:
- 수치형 데이터의 경우, 결측값을 해당 변수의 평균값, 중앙값, 또는 최빈값으로 대체할 수 있습니다. 데이터 분포가 왜곡되지 않도록 주의해야 합니다.
- 예시: df['age'].fillna(df['age'].mean(), inplace=True) (결측값을 평균값으로 대체)
- 이전 값이나 다음 값으로 대체:
- 시계열 데이터에서 결측값이 있을 경우, 바로 이전 또는 다음 값으로 대체할 수 있습니다. 이는 데이터가 시간에 따라 연속적일 때 유용합니다.
- 예시: df.fillna(method='ffill') (이전 값으로 채우기)
- 모델 기반 대체:
- 머신러닝 모델을 사용하여 결측값을 예측하는 방법입니다. 예측 모델을 사용하여 결측값을 추정하고 대체할 수 있습니다.
- 예시: 회귀 분석 또는 k-최근접 이웃(k-NN) 알고리즘으로 결측값을 예측
- 'Missing'으로 간주하여 별도의 범주로 처리:
- 범주형 데이터에서 결측값을 별도의 범주로 처리할 수 있습니다. 이는 결측값이 의미가 있는 경우에 유용합니다.
- 예시: df['category'].fillna('Missing', inplace=True)
결측값 처리 방법은 데이터 분석의 정확성에 중요한 영향을 미치므로, 데이터의 특성을 잘 파악한 후 적절한 방법을 선택하는 것이 중요합니다.
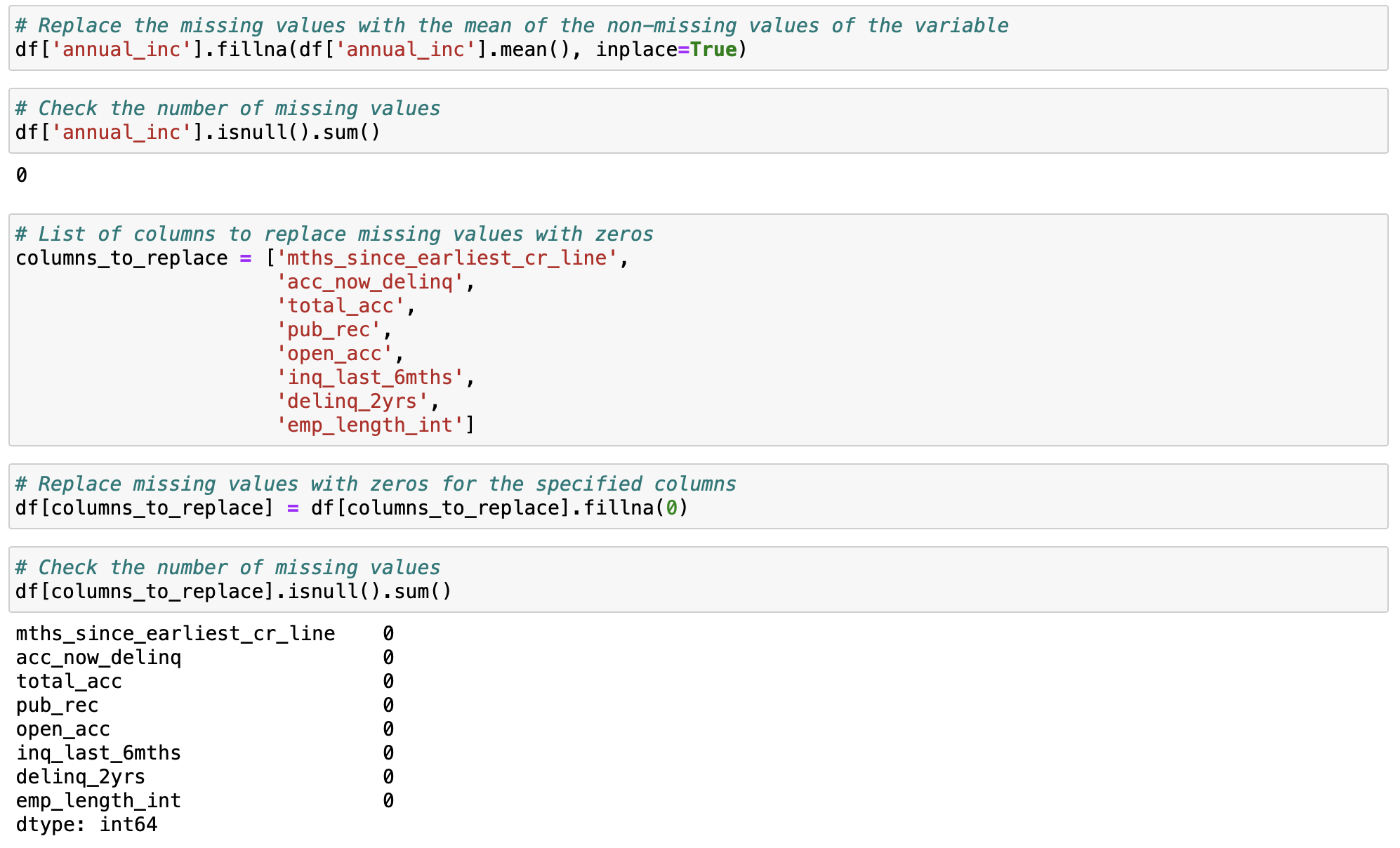
annual_inc(연소득) 열에서 결측값을 그 열의 평균값으로 대체했습니다. columns_to_replace 리스트에 지정된 열들에 대해 결측값을 0으로 대체했습니다. 여기에는 신용 기록이나 대출 관련 열들이 포함되어 있습니다. 결측값이 의미하는 바를 고려하여 해당 항목이 존재하지 않음을 의미하는 0으로 처리합니다. 또한, total_rev_hi_lim(총 회전 신용 한도) 열에서 결측값을 funded_amnt(배정된 대출 금액) 열의 값으로 대체했습니다. 이는 결측값이 존재할 때 신용 한도를 해당 대출 금액으로 대체하여 데이터 완성도를 높입니다.
다음 포스팅에서 이어집니다.
'Data Science > Project' 카테고리의 다른 글
| 데이터 사이언스 프로젝트 (신용 리스크 모델링) 2 | 데이터셋 설명 (4) | 2024.09.07 |
|---|---|
| 데이터 사이언스 프로젝트 (신용 리스크 모델링) 1 | 신용 위험(credit risk)은 무엇이며 왜 중요한가요? (4) | 2024.09.05 |